Multiple Choice
Identify the choice that best completes the statement or answers
the question.
|
|
|
1.
|
Secondary data is data that is
collected:
a. | About secondary school students | b. | During the second part of the
study | c. | By the person conducting the research | d. | By someone other than the person conducting the
research |
|
|
|
2.
|
Ryan surveys 300 students to find out their favourite TV show. The most
appropriate method to display his data would be a:
a. | Bar graph | b. | Frequency polygon | c. | Histogram | d. | Box-and-whisker
plot |
|
|
|
3.
|
Which of the following is NOT a measure of
dispersion in a set of data?
a. | mean | b. | interquartile range | c. | variance | d. | standard
deviation
|
|
|
|
4.
|
The formula below will determine the 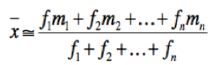 a. | population mean | b. | sample mean | c. | mode | d. | median | e. | grouped data
average | f. | weighted average |
|
|
|
5.
|
This formula will calculate the  a. | population mean | b. | mode | c. | median | d. | sample mean | e. | weighted
average | f. | grouped data median |
|
|
|
6.
|
Below are the investment weightings of each time of investment for Bob, Pavneet,
and Jose. | Investments | Return% | Bob’s weights | Pavneet’s weights | Jose’s weights | | Cash | 0 | 10 | 10 | 25 | | Bond fund | 10 | 20 | 20 | 40 | | Income fund | 15 | 20 | 50 | 30 | | Growth fund | -5 | 50 | 20 | 5 | | | | | |
Based on the information in the chart above, which investment
portfolio will have the highest investment growth? a. | Bob | b. | Pavneet | c. | Jose | d. | None of them |
|
|
|
7.
|
Which of the following is not true about the mode:
a. | The mode is usually less useful than the median or mean | b. | A data set may have
more than one mode | c. | It is possible for a data set to have no
mode | d. | Every data set has a mode |
|
|
|
8.
|
Which of the following is not true about the median
a. | It is generally a good measure of central tendency | b. | Every data set has a
median | c. | The median is not as susceptable to being skewed by outliers | d. | It is easier to
calculate than the mean or mode |
|
|
|
9.
|
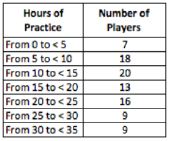 What is the mean of the data set
above? a. | 13.14 | b. | 17.5 | c. | 218.57 | d. | 16.6 |
|
|
|
10.
|
Why is mean, median, or mode never enough to describe a data set on their
own?
a. | You don’t know what the min and max values are | b. | You don’t know
how the individual data points are distributed throughout the range | c. | You can’t tell
if there is more than one central tendency to the data | d. | all of these answers are
correct. |
|
|
|
11.
|
One of the best and most-used tools to visualize one variable statistics that
eliminates many of the limitations of mean, median and mode is a
a. | Scatter plot | b. | Bar graph | c. | Line
graph | d. | Histogram | e. | Pie grapm |
|
|
|
12.
|
What is the independent variable in a correlational study of amounts of sunlight
and the heights of tomato plants?
a. | the types of tomato plants | b. | the heights of the tomato
plants | c. | the angle of the sun | d. | the numbers of hours of
sunlight |
|
|
|
13.
|
Discuss the observation that “Drivers of red cars are twice as likely to
be involved in an accident as drivers of blue cars.” Does this imply that driving a red car
“causes” drivers to have an accident? What is the relationship here?
a. | causation | b. | common cause | c. | coincidence | d. | none of the
above |
|
|
|
14.
|
A higher number of ice cream sales corresponds to a higher number of shark
attacks on swimmers.
a. | causation | b. | common cause | c. | coincidence | d. | none of the
above |
|
|
|
15.
|
Which of the following is the dependent variable?
a. | heart disease | b. | cholesterol level | c. | could be
either |
|
|
|
16.
|
Which of the following is the dependent variable?
a. | hours of basketball practice | b. | free-throw success rate | c. | could be
either |
|
|
|
17.
|
Which of the following is the dependent variable?
a. | running speed | b. | pulse rate | c. | could be
either |
|
|
|
18.
|
Which set of data would probably show a strong positive linear
correlation?
a. | marks on a history test and the heights of the students | b. | the number of
defective light bulbs produced and the time of the day when they were
manufactured | c. | the colour of cars sold and the annual income of the car buyers | d. | the hight of the
corn in a field and the amount of precipitation during the growing
season |
|
|
|
19.
|
Which set of data would probably show a strong negative linear
correlation?
a. | resale values of computers and their ages | b. | heights of
volleyball players can jump and the strength of their leg muscles | c. | numbers of people at
a water park and the air temperature | d. | scores on a mathematics test and the number of
hours spent studying for it |
|
|
|
20.
|
If the rate of ozone depletion and the temperature were shown to be negatively
correlated, then
a. | a low rate of depletion would occur at lower temperatures | b. | a high rate of
depletion would occur at higher temperatures | c. | a low rate of depletion would occur at higher
temperatures | d. | a high rate of depletion would occur at lower temperatures | e. | (a) and (b) are
correct | f. | (c) and (d) are correct | g. | None are
correct |
|
|
|
21.
|
A set of data with a correlation coefficient of –0.55 has a
a. | strong negative linear correlation | b. | moderate negative linear
correlation | c. | weak negative linear correlation | d. | little or no linear
correlation |
|
|
|
22.
|
The correlation coefficient for weed growth in a lake and temperature was found
to be 0.915. The scatter plot for the data would have
a. | an array of dots with no discernible pattern to them | b. | dots clustered in a
linear fashion sloping up to the left | c. | dots tightly clustered in a linear
fashion sloping up to the right | d. | a cluster of dots in the middle of the
graph |
|
|
|
23.
|
For the line of best fit in the least-squares method,
a. | the sum of the squares of the residuals (squared error) has the greatest possible
value | b. | the sum of the squares of the residuals (squared error) has the least possible
value | c. | the sum of the residuals is equal to one | d. | both (b) and
(c) |
|
|
|
24.
|
An outlier is a data point that
a. | should sometimes be left out of a statistical analysis | b. | may be an abnormal
result | c. | may significantly affect the calculation of the correlation
coefficient | d. | all of these are correct |
|
|
|
25.
|
The coefficient of determination (the goodness of fit), r2,
indicates
a. | the linear relationship between two variables | b. | the slope of the
line of best fit (i.e. the regression line) | c. | how closely the data fit a defined
curve | d. | the percentage of squared (residual) error removed by
regression |
|
|
|
26.
|
Observe the graphs below. 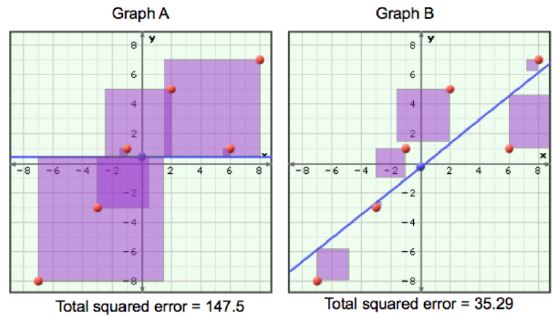 The y-values are daily
maximum temperatures, their average is 0.5 degrees celcius. The purple squares in graph A indicate
the squared error from using a simple average temperature (the line is y=0.5) to predict the value of
a single data point. In graph B the squared error is from using a model of linear regression to
predict temperature. Thus, the value of the coefficient of determination (the goodness of fit),
r 2 for the linear model in graph B is likely: a. | 0.21 | b. | zero | c. | 0.97 | d. | 0.76 | e. | 61.0 |
|
|
|
27.
|
The population of certain species of animals decreases as logging in wilderness
areas increases is most likely an example of a
a. | causal (i.e. cause-and-effect) relationship | b. | common cause
relationship (i.e. both are related to some third unknown variable) | c. | coincidental
relationship |
|
|
|
28.
|
The sales of sports cars increase as the school year comes to a close in June is
most likely an example of a
a. | causal (i.e. cause-and-effect) relationship | b. | common cause
relationship (i.e. both are related to some third unknown variable) | c. | coincidental
relationship |
|
|
|
29.
|
The price of bread and canola oil both increase sharply after the prairies
experience a drought during the growing season is most likely an example of a
a. | causal (i.e. cause-and-effect) relationship | b. | common cause
relationship (i.e. both are related to some third unknown variable) | c. | coincidental
relationship |
|
|
|
30.
|
Studies find that consumption of vitamin C reduces the number and severity of
colds that people get is most likely an example of a
a. | causal (i.e. cause-and-effect) relationship | b. | common cause
relationship (i.e. both are related to some third unknown variable) | c. | coincidental
relationship |
|
|
|
31.
|
The longer you spend sleeping on your right side the more likely it will be a
sunny day in the morning is most likely an example of a
a. | causal (i.e. cause-and-effect) relationship | b. | common cause
relationship (i.e. both are related to some third unknown variable) | c. | coincidental
relationship |
|
|
|
32.
|
The current world price of crude oil increases as the price of gasoline at the
pump increase is most likely an example of a
a. | causal (i.e. cause-and-effect) relationship | b. | common cause
relationship (i.e. both are related to some third unknown variable) | c. | coincidental
relationship |
|
|
|
33.
|
Does the slope of a line of regression (line of best fit)
tell you anything (on its own) about the relationship between two variables?
a. | yes, lots | b. | almost nothing | c. | nothing | d. | none of these answers is
correct |
|
|
|
The coach of the Statsville football team wants to determine if there is a
relationship between how fast players can run 60 m and how far they can throw the football. The
results for the Statsville players are graphed in the scatterplot below.

|
|
|
34.
|
Based on the scatter plot, are there any data points that could be identified as
outliers?
a. | Yes, one. | b. | Yes, two. | c. | No,
none | d. | There are several. |
|
|
|
35.
|
If the regression line for this scatter plot is: Throwing Distance =
-3(Sprint Time) + 50, then use the model to predict the throwing distance of an athlete who
can sprint 60m in 5 seconds.
a. | 68.6 m | b. | 50 m | c. | 40
m | d. |
35 m |
e. | The answer is not on this
list |
|
|
|
36.
|
Based on the scatter plot (ignoring any outliers), what type of relationship
exists between the two variables?
a. | Weak positive relationship | b. | Strong positive
relationship | c. | Weak negative relationship | d. | Strong negative
relationship | e. | No relationship |
|
|
|
37.
|
Which one of the following images showing relationships on a scatter plot would
have a correlation coefficient of r = 0.6? 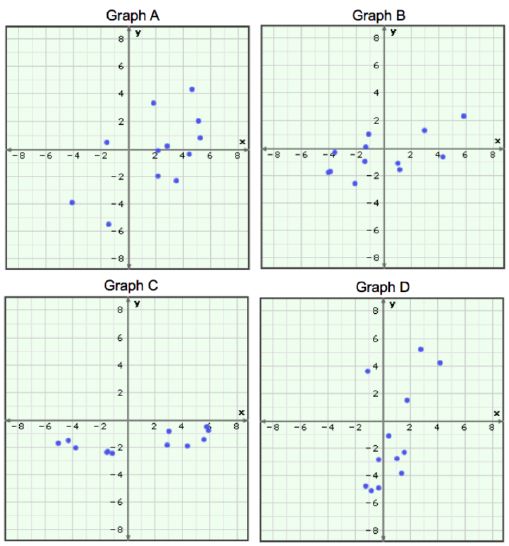 a. | graph A | b. | graph B | c. | graph
C | d. | graph D | e. | all of them | f. | none of
them |
|
Matching
|
|
|
Match the following terms to their definition below.
a. | Categorical | k. | Outlier | b. | Census | l. | Percentile | c. | Continuous | m. | Population | d. | Discrete | n. | Quartile | e. | Interquartile
range | o. | Range | f. | Mean | p. | Sample | g. | Mean absolute
deviation | q. | Sample
deviation | h. | Median | r. | Sampling frame | i. | Mode | s. | Standard deviation | j. | Ordinal | t. | Variance |
|
|
|
38.
|
The set of all individuals who belong to the group being studied by a
survey.
|
|
|
39.
|
In a set of data, the sum of the values of a variable divided by the total
number of values.
|
|
|
40.
|
When a set of data is ranked from the highest value to the lowest, the middle
value is called...
|
|
|
41.
|
The value that occurs most frequently in a set of data is the...
|
|
|
42.
|
A value that is distant from the
majority of values in a set of data.
|
|
|
43.
|
The body or group from which a sample is selected.
|
|
|
44.
|
Divide a set of ranked data into one hundred groups with equal numbers of
values. A single group is called...
|
|
|
45.
|
The square root of the variance measures the typical deviation a single data
point will have from the mean. It is called...
|